Thursday, August 7, 2025
Implementing AI function calling with Express and Azure OpenAI

Context
The context of this entry is the natural technical evolution— from simply requesting a response from Azure OpenAI, to later understanding the need for streaming responses, and now to enabling the model to call functions we make available.
As mentioned, when we allow the model decide if it is required to use functions as tools. The model — just like humans — becomes significantly more useful, especially when equipped with the right ones.
The implementation is quite straightforward, though there are some considerations to be aware of.
TLDRS
You can find all code in the following Github repository.
Scope
Maintaining simplicity as a core principle, the goal of this entry is to equip our solution with the ability to recognize the need to use a tool — a function that exists solely within our workspace.
Additionally, this integration acknowledges the technical challenges previously covered in earlier entries.
- Reducing response latency through data streaming to optimize the user experience.
Implementation
To begin the implementation, let’s take a look at the official documentation of function calling from OpenAI.
[…] The model may decide to call these functions — instead of (or in addition to) generating text or audio. You’ll then execute the function code, send back the results, and the model will incorporate them into its final response.
We can highlight a simplify workflow:
1. I will send a message which includes the tools available
2. The model might decide to use them or not. If so I have to execute the function and send back the result.
3. The model will take this answer and reply back.
We can take a look at the workflow in the following diagram.
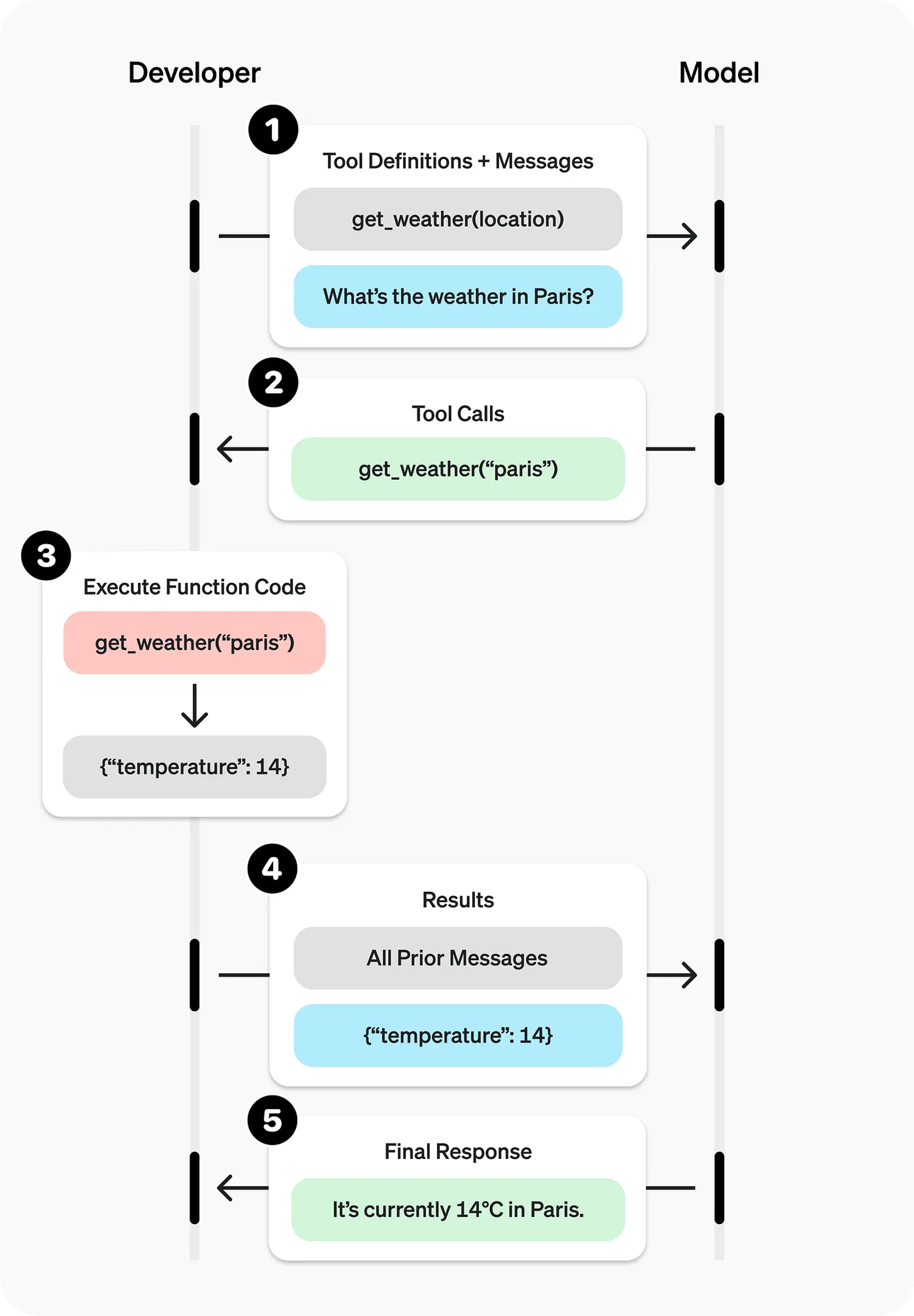
Here is a key questions:
- If I have to send the model two messages, how should I structure them so that the model understands the sequence?
To understand the answer, we first need to understand how to handle a conversation with the model. Having conversations with a model has been a crucial evolution for the stability and security of interactions with language models. I (highly) recommend reading OpenAI’s Model Spec.
It presents, in a simple and coherent way, the rules and the chain of command — like the levels of authority — to ensure the AI’s behavior is consistent and predictable.
Implementing a conversation format
A simple test would be to restructure the request as follows:
- Our API will take the role of user, and the input from the request will be appended as content to the message.
The model will take the role of assistant, and its responses will be appended as content to the message — creating a base payload format.
const userMessages = [
{ role: "user", content: req.body.input }
];
const basePayload = {
input: JSON.stringify(userMessages),
model: req.body.model || "o4-mini",
tools: tools,
tool_choice: "auto",
stream: true
};Please note that we are in a scenario where the output of the assistant is consumed by an application — in this case, our API — and is typically required to follow a precise format.
Next, let’s define the tool that will be available to the model.
export const tools = [
{
type: "function",
name: "getWeather",
description: "Gets the current weather in a given city",
parameters: {
type: "object",
properties: {
location: {
type: "string",
description: "City and country e.g. Arica, Chile"
}
},
required: [
"location"
],
additionalProperties: false
}
}
];
type Props = { location : string };
export const getWeather = async ({ location }: Props): Promise<Weather> => {
const rawData = {
location,
temperature: "22°C",
condition: "Partly cloudy"
};
return weatherSchema.parse(rawData);
};We are going to implement the first request and format the streaming result.
const initialRequest = await fetch(env.AZURE_ENDPOINT, {
method: "POST",
headers: {
"Content-Type": "application/json;",
"Authorization": `Bearer ${env.AZURE_API_KEY}`
},
body: JSON.stringify(basePayload)
});
if (!initialRequest.ok || !initialRequest.body) {
const err = await initialRequest.text();
res.write(`event: error\ndata: ${err}\n\n`);
res.end();
return;
}
const reader = initialRequest.body.getReader();
const decoder = new TextDecoder("utf-8");
As a basic implementation, I’m going to define a flag to detect whether the response includes a tool call. As the diagram guided us, if a tool is required, we need to identify the function name and perform that function call.
Next, with the result from that call, we create an upgraded messages array that is ready for the second request.
let toolTriggered = false;
let updatedMessages = [...userMessages];
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
const lines = chunk.split("\n");
for (const line of lines) {
if (!line.startsWith("data: ")) continue;
const json = line.replace(/^data:\s*/, "");
if (json === "[DONE]") continue;
const parsed = JSON.parse(json);
const outputs = get(parsed, "response.output", []);
const type = get(parsed, "type");
if (type === "response.completed" && outputs.length > 0) {
for (const output of outputs) {
const status = get(output, "status");
const outputType = get(output, "type");
if (status === "completed" && outputType === "function_call") {
const name = get(output, "name");
const params = JSON.parse(get(output, "arguments"));
const callId = get(output, "call_id");
if (name === "getWeather") {
toolTriggered = true;
const tool_response = await getWeather(params);
updatedMessages = [
...userMessages,
output,
{
type: "function_call_output",
call_id: callId,
output: tool_response
}
];
}
}
}
if (toolTriggered) {
await reader.cancel();
break;
}
}
res.write(`data: ${json}\n\n`);
}
if (toolTriggered) break;
}Finally, we perform the second request in a fresh new iteration, while continuing to stream the results.
if (toolTriggered) {
const secondPayload = {
input: JSON.stringify(updatedMessages),
model: req.body.model || "o4-mini",
tools: tools,
stream: true
};
const secondRequest = await fetch(env.AZURE_ENDPOINT, {
method: "POST",
headers: {
"Content-Type": "application/json;",
"Authorization": `Bearer ${env.AZURE_API_KEY}`
},
body: JSON.stringify(secondPayload)
});
if (!secondRequest.ok || !secondRequest.body){
const err = await secondRequest.text();
res.write(`event: error\ndata: ${err}\n\n`);
res.end();
return;
}
const secondRequestbody = secondRequest.body
const reader = secondRequestbody.getReader();
const decoder = new TextDecoder("utf-8");
let isDone = false;
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
for (const line of chunk.split("\n")) {
if (line.startsWith("data: ")) {
const json = line.replace(/^data:\s*/, "");
if (json === "[DONE]") {
res.write("event: done\ndata: [DONE]\n\n");
res.end();
return;
}
res.write(`data: ${json}\n\n`);
}
}
}
if (!isDone) {
res.write("event: done\ndata: [DONE]\n\n");
}
res.end();
}
It was a straightforward, point-by-point workflow implementation. We can later consider refactoring the streaming process. As a basic implementation, let’s see if it works first.
Testing
Let’s start by testing a scenario where no tool is needed.
curl -N -H "Content-Type: application/json" \ 3s 18:28:53
-X POST http://localhost:4000/v1/chat \
-d '{
"model": "o4-mini",
"input": "what are things I should do in Coyhaique, Chile. explain briefly? short and simple"
}'
...
"output": [
...
{
"status": "completed",
"content": [{
...
"text": "Here are a few must-do activities in and around Coyhaique, ..."
}],
"role": "assistant"
}],And let’s test a scenario where a tool is actually needed.
curl -N -H "Content-Type: application/json" \
-X POST http://localhost:4000/v1/chat \
-d '{
"input": "what is the weather like in Coyhaique, Chile today?"
}'
...
{
"item": {
"type": "function_call",
"status": "completed",
"arguments": "{\"location\":\"Coyhaique, Chile\"}",
"call_id": "call_sz...",
"name": "getWeather"
}
}
...
"output": [
...
{
"status": "completed",
"content": [{
...
"text": "Today in Coyhaique, Chile it's partly cloudy with a temperature of about 22°C."
}],
"role": "assistant"
}],All seems correct.
Conclusions
One thing I’ve noticed throughout these implementations is the number of functionalities required to build a solution that might include an interface with a person.
So far, I have only considered backend logic, but after implementing the most basic API interaction, I already found the need to stream responses to compensate for latency; manage dynamic flows to handle responses without compromising token cost; and keep the context window healthy.
Sure thing, I could opt for a brute force approach, like most paths I’ve taken. However, this opens the door to several more interesting questions:
- How can I evaluate the results of my solution according to my implementation?
- How can I implement a minimum level of cost control?
Operational excellence
The importance of implementing some form of observability is crearly critical. Exposing a solution with a cost model based on tokens sent and received, without any level of monitoring, is not advisable.
The risks of running a AI-based solution in production blindly are simply too high to postpone them.
Next steps
I consider this implementation series complete, paving the way for the next entries: testing an approach more focused on adding intelligence to business workflows.