Monday, August 4, 2025
Implementing Streaming Responses with Express and Azure OpenAI

Context
Based on the previous article, I’ve shown how to establish HTTP communication between a client of our choice and a model provider.
It’s clear that while establishing the communication can be trivial, it comes with latency limitations, revealing how operating with a Request <> Response model leaves us with a User Experience debt we can’t ignore.
What we can do instead is request that tokens be sent to us as soon as they’re available, rather than waiting for the full response to be completed. In other words, we request a stream of data.
This doesn’t necessarily reduce the total time needed to generate the final response, but it significantly reduces the wait time for the first generated token.
TLDRS
You can find all code in the following Github repository.
Scope
We are in the point where if we want to build a modern applications we need to move beyond the simple request-response pattern.
The goal of this article is to enable data streaming with minimal and reliable configuration.
Core concepts
Let’s talk about SSE — a elegant way to stream updates from the API just built, and still using HTTP.
We consider SSE (Server-Sent Events) when we need to send real-time updates from the server to the client using a single, long-lived HTTP connection. This eliminates the need for the client to constantly request updates.
The following image shows, in general terms, how it would work in our implementation.
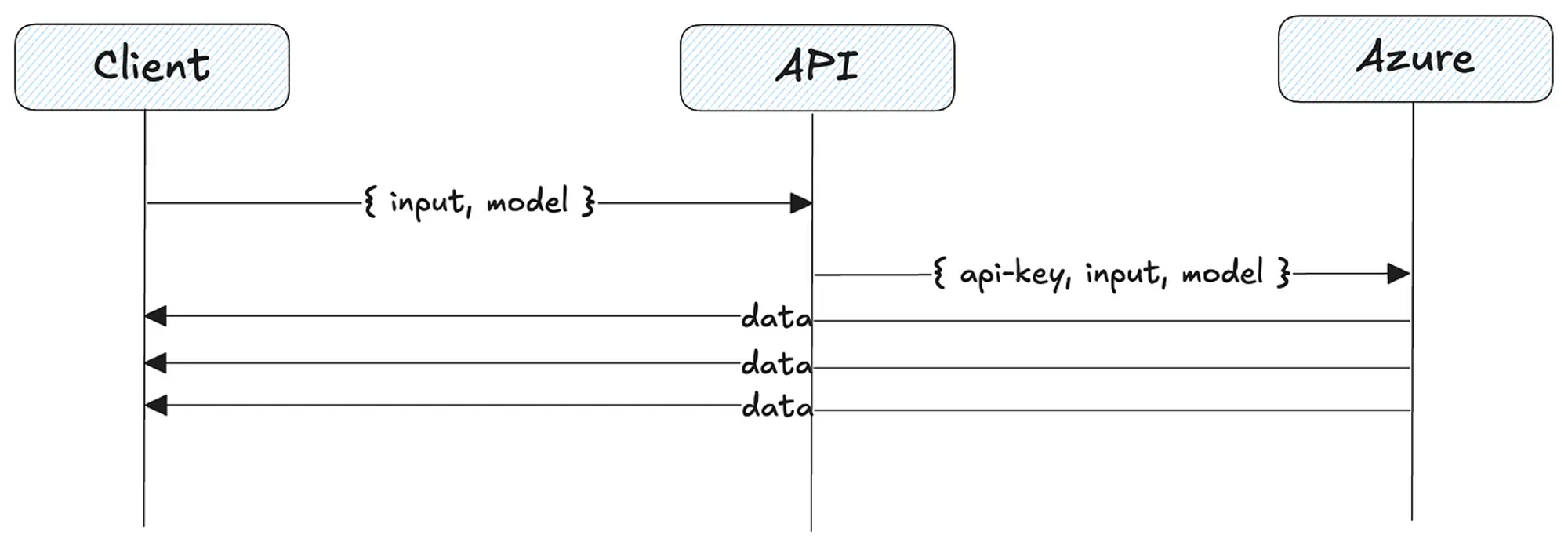
To simplify, it’s similar to using long-polling, but more efficient for one-way communication from the server to the client.
This makes simpler to implement and integrate into our existing HTTP infrastructure without the need for special protocol handling.
Why not WebSockets?
The simple and direct answer is that we’d be adding more complexity to something that was already covered with SSE.
If we want to use WebSockets, we need to consider the need for bidirectional communication, and real-time data.
For that, we must be aware that WebSockets require maintaining a connection between client and server.
In other words, operational overhead.
Requesting the response as a stream
Starting from the previous development, I need to upgrade the previous request call to Azure AI endpoint. Specifically, I must indicate that we want to receive the response as a stream.
To do this, it is required to add "stream": true to the payload.
// chat.controller.ts
export const chat = async (req: Request, res: Response) => {
res.setHeader("Content-Type", "text/event-stream");
res.setHeader("Cache-Control", "no-cache");
res.setHeader("Connection", "keep-alive");
const payload = {
input: req.body.input,
model: req.body.model || "o4-mini",
stream: true
};
try {
...
} catch (err) {
console.error("Streaming error:", err);
res.write(`event: error\ndata: ${JSON.stringify(err)}\n\n`);
res.end();
}
};It is also a good practice to set the appropriate headers of the response to the client who is requesting data to us, as streaming behavior is not guaranteed and may not be fully compliant with how clients like EventSource expect to receive data.
Processing the response
Next, the workflow has to check if Azure’s response was successful and has a body. If not, it can simply handle the error and end the connection right there.
Then, it has to continue by reading the response from Azure and convert it into valid SSE events.
After that, we filter and format each chunk so the client receives updates as soon as the events arrive. When all events have been received, the delta value in the response will be response.completed. That will be our flag.
try {
const azureRes = await fetch(env.AZURE_ENDPOINT, {
method: "POST",
headers: {
"Content-Type": "application/json;",
"Authorization": `Bearer ${env.AZURE_API_KEY}`
},
body: JSON.stringify(payload)
});
if (!azureRes.ok || !azureRes.body) {
const err = await azureRes.text();
res.write(`event: error\ndata: ${err}\n\n`);
res.end();
return;
}
const reader = azureRes.body.getReader();
const decoder = new TextDecoder("utf-8");
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
for (const line of chunk.split("\n")) {
if (line.startsWith("data: ")) {
const json = line.replace(/^data:\s*/, "");
const output = get(JSON.parse(json), "type", null)
if(output === "response.completed"){
res.write("event: done\ndata: [DONE]\n\n");
res.end();
return;
}
res.write(`data: ${json}\n\n`);
}
}
}
} catch (err) {
console.error("Streaming error:", err);
res.write(`event: error\ndata: ${JSON.stringify(err)}\n\n`);
res.end();
}Testing
That was it. In order to test if it works, we can use our terminal again and run the following curl:
curl -N -H "Content-Type: application/json" \
-X POST http://localhost:4000/v1/chat \
-d '{
"input": "what are things I should do in Coyhaique, Chile. explain briefly? short and simple"
}'You might get a result like this:
data: {"type":"response.created","sequence_number":0,"response":{"id":"resp_...","object":"response","created_at":1754262348,"status":"in_progress","background":false,"content_filters":null,"error":null,"incomplete_details":null,"instructions":null,"max_output_tokens":null,"max_tool_calls":null,"model":"o4-mini","output":[],"parallel_tool_calls":true,"previous_response_id":null,"prompt_cache_key":null,"reasoning":{"effort":"medium","summary":null},"safety_identifier":null,"service_tier":"auto","store":true,"temperature":1.0,"text":{"format":{"type":"text"}},"tool_choice":"auto","tools":[],"top_p":1.0,"truncation":"disabled","usage":null,"user":null,"metadata":{}}}
...
data: {"type":"response.output_text.delta","sequence_number":109,"item_id":"msg_...","output_index":1,"content_index":0,"delta":"."}
data: {"type":"response.output_text.done","sequence_number":110,"item_id":"msg_...","output_index":1,"content_index":0,"text":"Here are some quick ideas:\n\n• Hike Cerro Castillo Reserve – dramatic peaks, glacial lakes. \n• Explore Valle Simpson – forest trails and waterfalls. \n• Kayak or fish on the Río Simpson – easy river access. \n• Drive a stretch of the Carretera Austral – epic Patagonian views. \n• Sample Patagonian lamb asado and local craft beer in town. \n• Take a day trip to Queulat National Park – hanging glacier and fjords."}
data: {"type":"response.content_part.done","sequence_number":111,"item_id":"msg_...","output_index":1,"content_index":0,"part":{"type":"output_text","annotations":[],"text":"Here are some quick ideas:\n\n• Hike Cerro Castillo Reserve – dramatic peaks, glacial lakes. \n• Explore Valle Simpson – forest trails and waterfalls. \n• Kayak or fish on the Río Simpson – easy river access. \n• Drive a stretch of the Carretera Austral – epic Patagonian views. \n• Sample Patagonian lamb asado and local craft beer in town. \n• Take a day trip to Queulat National Park – hanging glacier and fjords."}}
data: {"type":"response.output_item.done","sequence_number":112,"output_index":1,"item":{"id":"msg_...","type":"message","status":"completed","content":[{"type":"output_text","annotations":[],"text":"Here are some quick ideas:\n\n• Hike Cerro Castillo Reserve – dramatic peaks, glacial lakes. \n• Explore Valle Simpson – forest trails and waterfalls. \n• Kayak or fish on the Río Simpson – easy river access. \n• Drive a stretch of the Carretera Austral – epic Patagonian views. \n• Sample Patagonian lamb asado and local craft beer in town. \n• Take a day trip to Queulat National Park – hanging glacier and fjords."}],"role":"assistant"}}
event: done
data: [DONE]
I can see that as a success.
Conclusions
Having improved how we receive information, it’s important to realize that we’ve satisfied one requirement but introduced another. If we’re receiving data continuously until the server ends the stream, we need to account for this flow when defining our architecture.
If we place any proxy in front of our solution, we must be ready to handle increased complexity during debugging. We also need to keep in mind any cache invalidation policies and/or TTL definitions.
Equally important is the client-side implementation now that we’re streaming data. If we’re building a modern web application, it must support continuous data flow.
Again, we moved away from Request <> Response.
The right balance between the current implementation and the previous one lies in our ability to accept the tradeoffs each option presents.
In the long run, it’s important to evaluate the cost-benefit trade-offs of implementing observability, monitoring, security, and scalability measures.
Next steps
For the next entry, it will be interesting to implement the function calling feature, which is available in some OpenAI models.